
dbt モデルの configuration について挙動を確認してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは!よしななです。
前回の記事では、dbt jinja 関数の {{ref}}と{{source}}について挙動を確かめ、ご紹介しました。
今回は、dbt モデルの configuration について挙動を実際に確かめたので、ブログに備忘録としてまとめます。
〇目次
- 前提
- 対象環境
- コード実行のための準備
- データとテーブルの準備
- dbt プロジェクトファイルの作成
- dbt モデル構成について
- dbtモデルに記載した{{ config }} jinja関数
- ./test_jinja/models ディレクトリ配下の .yml ファイル
- .yml ファイルの命名規則について
- dbt_project.yml 内
- dbt モデル構成の設定場所
- dbt モデル構成のプロパティ
- 標準構成
- まとめ
- 参考文献
前提
対象環境
本ブログのコードは以下の環境で実行しています。
- OS
- Windows 11
- ターミナル
- VSCode / PowerShell で実行
コード実行のための準備
本ブログのコードを実行するには、以下の準備が必要です。
今回は、以下の準備がすべて完了した前提で進めます。
- dbt-core インストール
- Amazon Athena と dbt-core を接続する
dbt initコマンドを実行し、dbt モデルを格納するフォルダtest_jinjaを作成
データとテーブルの準備
.csv データの準備
下記の transaction_data_raw.csv は ChatGPT を使用して生成しています。
- employee_list.csv
employee_id,employee_name,department,job,age
1,john doe,sales,manager,35
2,jane smith,it,developer,28
3,michael johnson,finance,accountant,42
4,emily davis,hr,specialist,31
5,david wilson,marketing,coordinator,27
6,sarah lee,operations,supervisor,39
7,tom brown,r&d,researcher,33
8,olivia taylor,customer service,representative,25
9,daniel anderson,logistics,analyst,37
10,sophia martinez,legal,paralegal,29
テーブル作成
上記の employee_list.csv データをもとに、以下のDDL文を実行し Amazon Athena 上にemployee_list_tableを作成します。
- employee_list_table を作成する DDL
CREATE EXTERNAL TABLE `employee_list_table`(
`employee_id` int,
`employee_name` string,
`department` string,
`job` string,
`age` int
)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.OpenCSVSerde'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'{.csvを配置したS3バケット名}'
TBLPROPERTIES (
'classification'='csv',
'columnsOrdered'='false',
'compressionType'='none',
'delimiter'=',',
'skip.header.line.count'='1')
dbt プロジェクトファイルの作成
dbt initを実行し、作成したtest_jinjaプロジェクトの models フォルダ配下に dbt モデル:employee_list.sqlを作成しておきます。
Amazon Athena で作成したemployee_list_tableに対し、select * fromする SQL を記述します。
- employee_list.sql
select *
from employee_list_table
dbt モデル構成について
dbt モデルの構成・設計を定義するために、configuration を使用します。
configuration を設定するファイルは以下の通り3か所あります。
- dbt モデルに記載した
{{ config }}jinja 関数 - ./test_jinja/models ディレクトリ配下の .yml ファイル内
- dbt_project.yml 内
configuration を設定するファイルの記述について、本項で解説します。
dbt モデルに記載した {{ config }} jinja 関数
{{ config }}jinja 関数を使用して、直接 dbt モデル:employee_listに configuration を設定します。
以下の記法の通り、作成した先頭に{{ config }}を記述し、その下にモデルのロジックを記述します。
dbt モデル独自の設定がある場合、{{ config }}を使用します。
〇記法:
{{
config(
enable="true"
materialized= "table"
)
}}
select *
from employee_list_table
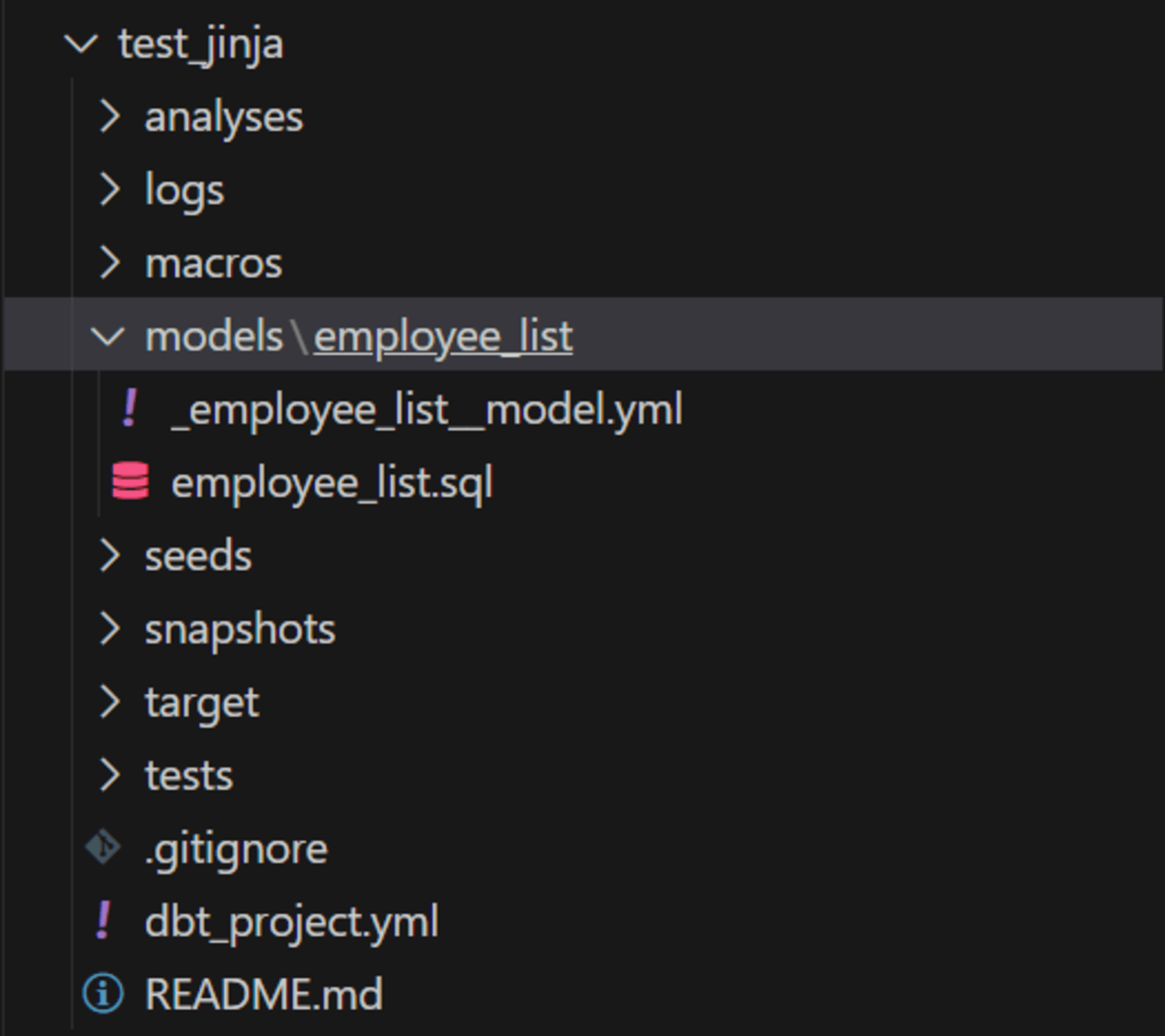
./test_jinja/models ディレクトリ配下の .yml ファイル
./test_jinja/models 配下の dbt モデル:employee_listに対し、以下の通り configuration を設定します。
- ./test_jinja/models/employee_list ディレクトリを作成
- 作成したディレクトリ内に
_employee_list__models.ymlを作成 _employee_list__models.ymlに configuration を記述
.yml ファイルの命名規則について
.yml ファイルは .sql モデルファイルのように一意の名前は必要ないですが、検索の利便性を高めるため、_{ディレクトリ名}__models.ymlと命名することがドキュメントで推奨されています。
先頭にアンダースコアをつけることで、.yml ファイルがすべてのフォルダーの先頭にソートされ、モデルから分離しやすくなります。
テーブルの参照先を指定する__source.ymlと configuration を指定する__models.ymlを一つにまとめることも可能ですが、configuration を探すのが煩雑になるためドキュメントでは分離が推奨されています。
参考ドキュメント:
〇記法:
version: 2
models: test_jinja
- name: employee_list
config:
enabled: true
materialized: view
models:名と dbt モデル名(.sql ファイル名)が一致したとき、_{ディレクトリ名}__models.ymlの内容が dbt モデルに反映されます。
dbt_project.yml 内
dbt init実行時に ./test_jinja 配下で生成される dbt_project.yml 内に configuration を記述します。
dbt プロジェクト全体で configuration を適用したい場合は dbt_project.yml に記述します。
以下の通り、dbt_project.yml 内のmodels:配下に configuration を記述します。
〇記法:
name: test_jinja
models:
test_jinja:
employee_list:
+enabled: true
+materialized: view
...
dbt モデル構成の設定場所
dbt モデルの configuration を記述するファイルは以下の3種類あります。
| 設定場所 | 優先順位 |
|---|---|
dbt モデルに記載した {{ config }} jinja 関数 |
1 |
| ./test_jinja/models ディレクトリ配下に格納された .ymlファイル | 2 |
| dbt_project.yml | 3 |
config の設定は表に記載した優先順位の通り、dbt モデルに記載した {{ config }} jinja 関数が最優先で適用され、 次に ./test_jinja/models 配下の .yml ファイルが適用され、
最後に dbt_project.yml の設定が適用されます。
→優先順位が高い設定がある場合、下位の設定は優先順位が高い設定にオーバーライドされます。
dbt モデル構成のプロパティ
以下に、configuration の設定項目について、まとめます。
configuration 一覧のドキュメントは以下です。
今回は configuration の中から、よく見かけるものをピックアップしました。
標準構成
enabled
dbt モデルを有効化 / 無効化するためのオプションです。
こちらの値をfalseに設定すると、dbt run時にモデルを実行から除外できます。
〇./test_jinja/models/employee_list/_employee_list__models.yml
version: 2
models:
- name: employee_list
config:
enabled: true
〇実行結果:
enabled: true の場合
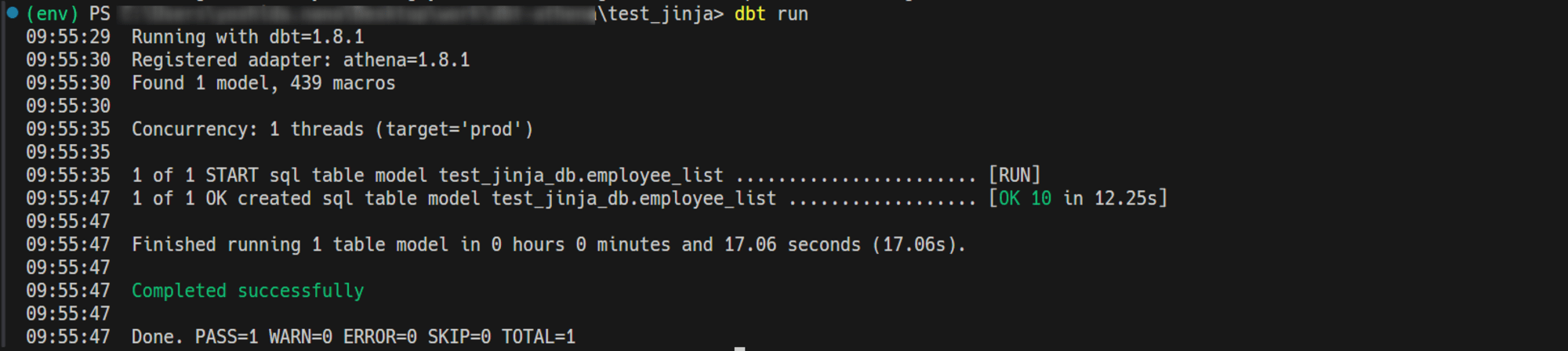
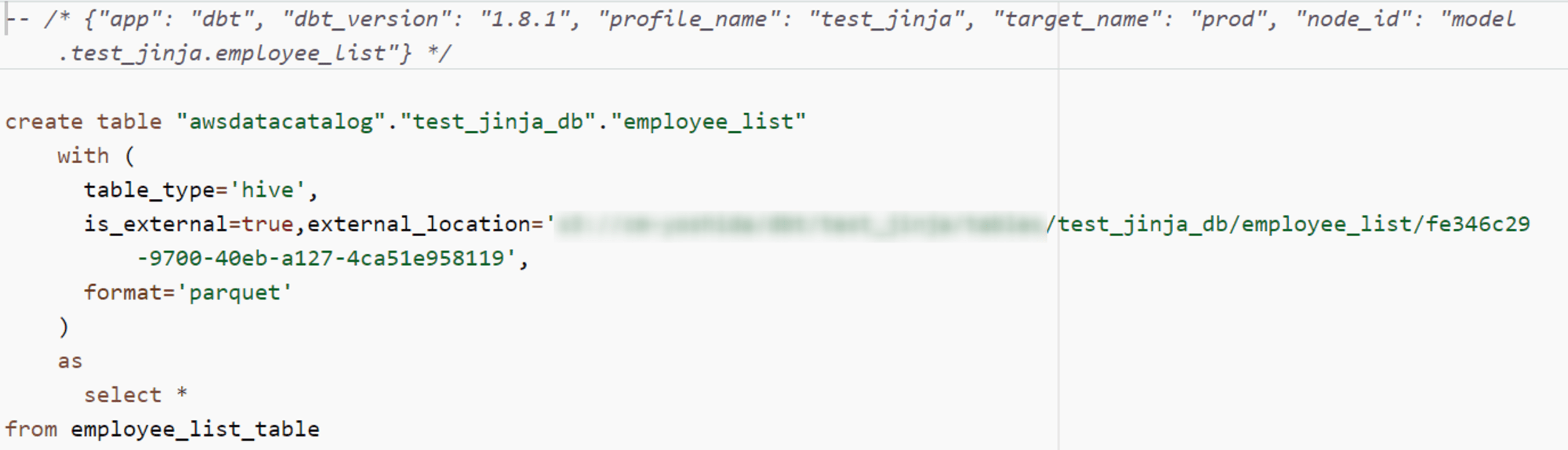
employee_listが実行されていることを確認しました。
enabled: false の場合

employee_listがdbt run時に実行されないことを確認しました。
tags
dbt モデルにタグ(またはタグのリスト)を付与できるオプションです。
モデルにタグを付与すると、dbt run などのコマンドを実行する際、タグごとに dbt モデルの実行が可能です。
dbt run --select tag:"{付与したタグ名}"でタグが付与されたモデルのみを実行することが可能です。
〇./test_jinja/models/employee_list/_employee_list__models.yml
version: 2
models:
- name: employee_list
config:
tags: my_tag
〇実行結果
_employee_list__models.ymlにtags: my_tagを付与してdbt run --select tag:my_tagを実行:
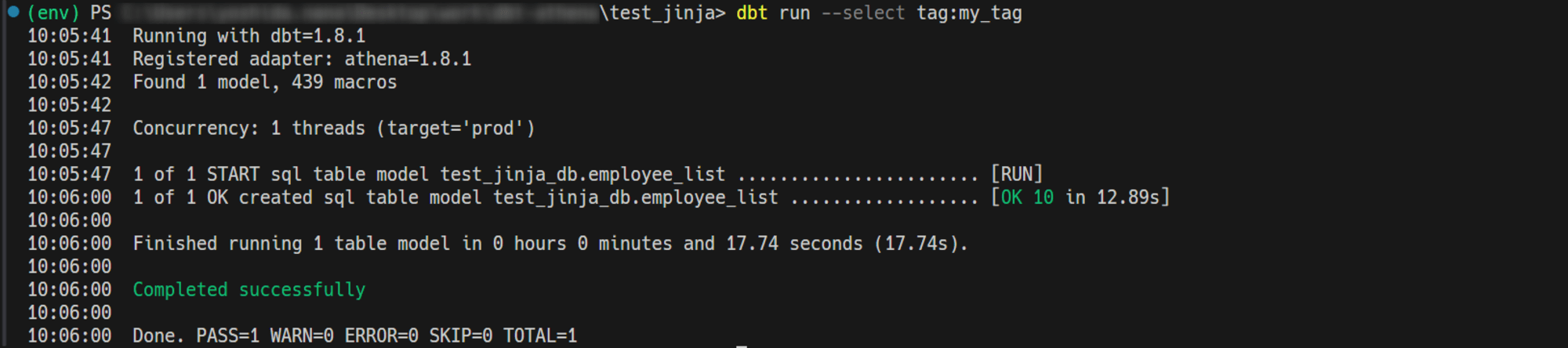
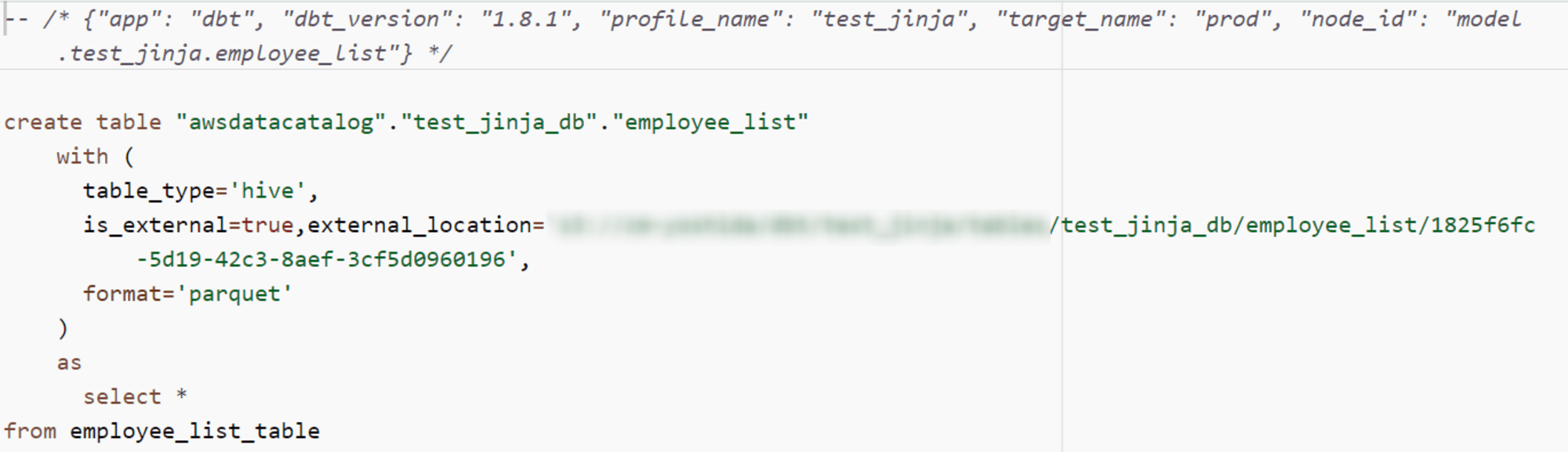
employee_listが実行されていることを確認しました。
_employee_list__models.ymlのtags: my_tagをtags: my_tag2に変更し、dbt run --select tag:my_tagを実行:

employee_listが dbt run時に実行されないことを確認しました。
pre_hook / post_hook
モデルの実行前 / 実行後に任意のSQLを実行可能なオプションです。
以下の通り、dbt モデルを実行後に Amazon Redshift のVACUUM処理を行う、といったことが可能です。
〇./test_jinja/models/employee_list.sql
{{
config(
post_hook= ['VACUUM {{ this }};']
)
}}
alias
実行モデルにエイリアス(別名)を付与することが可能なオプションです。
dbt のデフォルトの挙動では、.sql ファイル名がそのまま Amazon Athena などの dbt-core に接続したデータウェアハウスのテーブル名になります。
configuration にaliasを付与することにより、dbt モデルファイル(.sql ファイル)とdbt-core に接続したデータウェアハウスのテーブル名を別々に命名できます。
〇./test_jinja/employee_list/_employee_list__models.yml
version: 2
models:
- name: employee_list
config:
alias: employee_list_alias
〇実行結果
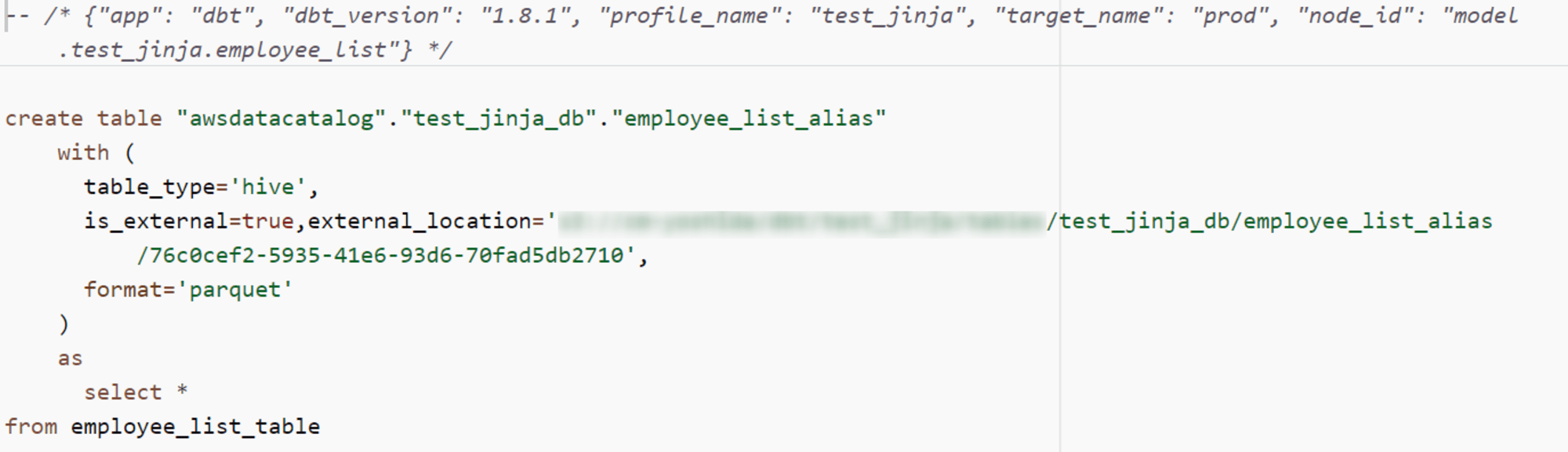
employee_list_aliasでcreat tableが実行されていることが確認できました。
.sql ファイル名と Amazon Athena のテーブル名が別々になっていることを確認しました。
まとめ
こちらで、「dbt モデルの configuration について挙動を確認してみた」は以上となります。
今回の記事では触れていませんが、dbt と接続しているデータウェアハウス毎に独自のconfiguration があるようなので、こちらも次回以降ご紹介できればと思います。
ここまで読んでいただきありがとうございました!
参考文献








